九州大学 システム情報科学府 情報理工学専攻 2019年度 計算機アーキテクチャ
Author
Yu
Description
【問 1】
以下の真理値表で与えられた論理関数 \(F(a, b, c, d)\) を図で示されるように関数 \(G(a, b, c, d)\) および NAND ゲートを使って実現することを考える。 関数 \(G\) の最簡積和形を示せ。
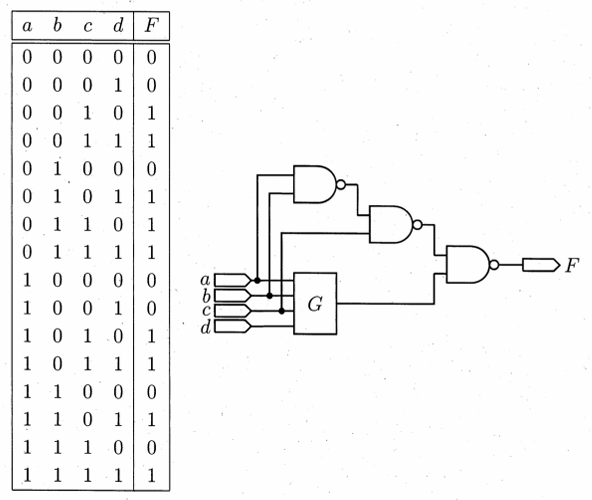
【問 2】
5 つのステージからなるパイプライン式データパスを有するマイクロプロセッサについて考える。 実装されたパイプラインステージは、IF(命令取得)、ID(命令デコード)、EX(実行)、MEM(メモリアクセス)、ならびに、WB(ライトバック)である。 以下の各問いに答えよ。
(1) パイプラインの導入によりプロセッサ性能が向上する理由を説明せよ。
(2) このパイプライン構造で発生する RAW(Read After Write)ハザードを解消する方法を少なくとも 2 つ挙げ、それぞれの実現法を簡潔に説明せよ。
(3) プログラム実行時間は、「実行命令数」「CPI(Clock cycles Per Instruction)」「クロックサイクル時間」の積で近似できる。このパイプラインのステージ数を増加した場合、改善を期待できる項目を選択し、その理由を説明せよ。
(4) 一般に、パイプライン段数を増加し続けた場合、プロセッサ性能向上の度合いは次第に小さくなる傾向にある。その理由を述べよ。
【問 3】
16 ビットのアドレス(adr[15:0])を入力とするダイレクトマップキャッシュの設計について考える。 バイトアドレッシング方式であり 1 語は 4 バイトとする。 各キャッシュアクセスにおいて、adr[15:8]、adr[7:4] ならびに adr[3:0] は、それぞれ、タグフィールド、インデックスフィールド、オフセットフィールドとして参照される。 以下の問いに答えよ。
(1) キャッシュブロックサイズを答えよ。
(2) キャッシュブロックの総数を答えよ。
(3) キャッシュの初期状態は空であるとする。以下の 16 進表現されたバイトアドレスに対してメモリアクセスが順次発生した場合のキャッシュ・ミス率を答えよ。
- 0x0000 ⇒ 0x0004 ⇒ 0x0020 ⇒ 0x1120 ⇒ 0x1104 ⇒ 0x0004 ⇒ 0x1120 ⇒ 0x0024 ⇒ 0x0020
Kai
【問 1】
| a | b | c | d | G |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 1 |
| 0 | 0 | 1 | 0 | x |
| 0 | 0 | 1 | 1 | x |
| 0 | 1 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | x |
| 0 | 1 | 1 | 1 | x |
| 1 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 1 | 1 |
| 1 | 0 | 1 | 0 | x |
| 1 | 0 | 1 | 1 | x |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 0 | 1 | 0 |
| 1 | 1 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| ab\cd | 00 | 01 | 11 | 10 |
|---|---|---|---|---|
| 00 | 1 | 1 | x | x |
| 01 | 1 | x | x | |
| 11 | 1 | 1 | ||
| 10 | 1 | 1 | x | x |
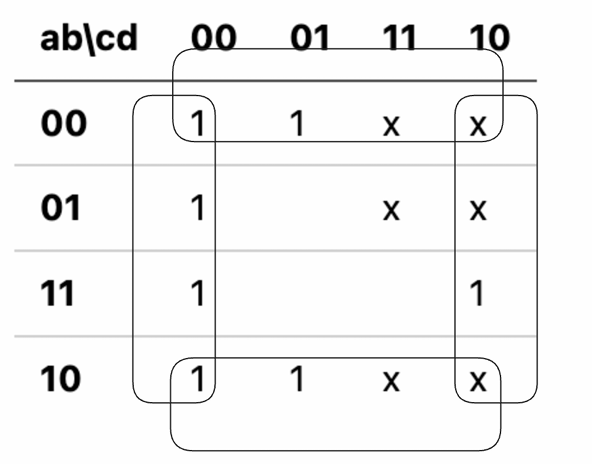
【問 2】
(1)
- 並⾏性の向上: パイプライン技術を使⽤することで、各ステージが同時に異なる命令を処理できます。これにより、プロセッサは複数の命令を同時に実⾏できるようになり、全体的なスループットが向上します。
- タスクの分割: パイプラインは、命令の実⾏をいくつかのステージに分割します。これにより、各ステージは特定のタスクに特化し、そのタスクを効率的に実⾏できます。これにより、命令の実⾏時間が短縮され、性能が向上します。
- クロックサイクルの短縮: 各ステージが独⽴して動作するため、クロックサイクルは各ステージの最も遅い部分に合わせる必要があります。これにより、クロックサイクルが短くなり、プロセッサの性能が向上します。
(2)
- ストール(Stall): ストールは、RAW ハザードが解消されるまで次の命令の実⾏を⼀時停止する方法です。これは、データが前の命令から利⽤可能になるまで待つことで、RAW ハザードを回避します。ただし、ストールはプロセッサの性能に悪影響を与える可能性があります。
- 実現方法:ハードウェアは、RAW ハザードが検出された場合、次の命令の実⾏を⼀時停止し、前の命令が書き込みを完了するのを待ちます。書き込みが完了したら、次の命令が再開され、ハザードが解消されます。
- フォワードィング(Forwarding)またはバイパス(Bypass): フォワードィングは、前の命令が書き込むデータを、次の命令がそれを読む前に直接転送する方法です。これにより、次の命令が待つことなくデータを読むことができ、RAW ハザードが解消されます。
- 実現方法:ハードウェアは、前の命令が書き込むデータを、次の命令がそれを必要とするステージに直接送信します。これにより、次の命令はデータを待たずに読むことができ、RAW ハザードが解消されます。
(3)
パイプラインのステージ数を増加させた場合、改善を期待できる項⽬は、「CPI(Clock cycles Per Instruction)」および/または「クロックサイクル時間」です。
パイプラインのステージ数を増やすことで、各ステージで⾏う作業が少なくなり、クロックサイクル時間が短くなる可能性があります。これにより、クロック周波数が速くなります。さらに、より多くのパイプラインステージが、より良い命令レベルの並列性につながり、平均CPIが低下する可能性があります。ただし、この改善は次第に減少する利益によって制限されます。
(4)
- 分岐予測の誤り率が増加する: パイプラインが深くなると、分岐予測が誤る可能性が増加し、パイプラインがしばしばフラッシュされることになります。これにより、性能向上が抑制されることがあります。
- パイプラインのバランスが悪化する: パイプライン段数が増加すると、各ステージの処理時間が異なる場合、最も遅いステージに従属することがあります。これにより、全体の性能が低下する可能性があります。
- プロセッサの複雑さが増加する: パイプライン段数が増加すると、プロセッサの設計や実装がより複雑になり、デバッグや最適化が困難になることがあります。また、消費電⼒やチップ⾯積も増加する可能性があります。
- 指令レベルの並列性 (ILP) の限界: プロセッサが同時に実⾏できる命令数には⾃然な限界があります。パイプライン段数を増加させても、その限界を超えることはできません。したがって、性能向上の度合いは次第に小さくなります。
【問 3】
(1)
\(16\) バイト
(2)
\(16\)
(3)
\(0.6\)